21P — Repetition Detector
Par admin le mardi, mai 11 2021, 12:00 - 2020–2021 - Lien permanent
Ce projet a été réalisé par CALLEGARI, David Rohan.
1. Introduction
Lorsque j'écris des textes plus ou moins longs, j'ai inévitablement tendance à faire un usage excessif et répétitif de certains mots, sans forcement m'en rendre compte. Cela d'autant plus quand j'écris en anglais, langue que je maîtrise plutôt bien mais dans laquelle j'ai tendance à trop me reposer sur des mots que je connais mieux pour exprimer certaines idées ou concepts.
Personnellement, je trouve que la répétition diminue souvent la qualité d'un texte, même si le contenu peut être qualitatif et pertinent. En effet, lorsque je lis un texte, une des premières choses que je remarque est la diversité de vocabulaire et si je retrouve continuellement le même mot, cela me gêne dans ma lecture et va d’emblée me biaiser vers une appréciation négative. Ainsi, à mes yeux, il peut arriver qu’une grande partie de la valeur positive d'un texte soit perdue ce qui est dommage, surtout si le texte est le mien, quand on considère à quel point ce détail semble anodin et pourrait être facilement corrigé si l’on s’en aperçoit.
En effet, pour parer à ce problème il suffirait de repérer les mots dont l’utilisation semble excessive par rapport à la longueur totale du texte et les remplacer par des synonymes.
Cependant, cette tâche peut vite se révéler plus longue et fastidieuse qu’il n’y paraît, si on doit analyser un texte très long. Or, après avoir passé des heures à rédiger, la volonté me manque souvent de tout relire "juste pour cela". De plus, après l'n-ème révision, j'ai beaucoup de mal à prendre du recul et relire le texte avec un regard neutre et favorable à la correction. Mais, lorsque je retombe sur des anciens documents que j'ai rendu pour l'une ou l'autre branche (notamment l'anglais), je constate assez vite quand j'utilise trop souvent un mot et cela me frustre beaucoup de penser à quel point ce texte aurait pu être meilleur et agréable à la lecture si ce "petit" détail avait été corrigé. Je pense aussi à la suite de mes études (EPFL etc...) lorsqu'il faudra rendre de longs rapports en anglais et que le soin du détail aura peut être plus d'importance qu'au gymnase. Je me dis alors qu'il faudrait trouver une solution efficace et facile à utiliser pour m'aider à ne plus commettre ce type d'erreurs-petites en apparence-mais qui, pour moi, peuvent faire toute la différence dans un texte.
Mon but pourrait donc être résumé en deux points: premièrement, améliorer la qualité de mon travail en obtenant un résultat qui soit vraiment propre et peaufiné et, deuxièmement, me faciliter la tâche et me permettre d'économiser du temps et de l'énergie lorsque je travailles sur des rendus.
Mon objectif pour atteindre ce but serait de créer un outil qui permet d'analyser et traiter des fichiers textuelles, en particulier des fichiers .odt puisque je travailles principalement avec LibreOffice. Cet outil devrait être assez simple et intuitif à utiliser afin de véritablement me simplifier la tâche et ne pas juste donner l'impression de le faire. Il devrait aussi amener quelque chose en plus qu'un simple control-F ne serait pas capable de fournir (compter les mots et fournir des synonymes par exemple).
2. Matériel et méthodes
2.1 Matériel
- 1 ordinateur avec python 3 ou une version ultérieure
2.2 Méthode
La réalisation de ce projet passe d'abord par le constat que les fichiers avec une extension OpenDocuments (.odt, .docx etc...) sont en réalité des archives zip. Ainsi, il est possible d'accéder au fichier en tant qu'archive zip, et en extraire le fichier (de type XML) qui contient le texte du document, grâce à la librairie zipfile. Ce programme requiert les librairies suivantes: re, os, xml.etree.ElementTree, nltk et zipfile.
Pour ce projet j'ai divisé le travail du logiciel en trois étapes principales : 1. extraire le fichier XML qui contient le texte; 2. l'analyser, compter les mots du texte et proposer de les substituer si ils apparaissent trop souvent; 3. rezipper le file avec la nouvelle version du fichier XML. Pour chacune de ces parties j'ai donc rédigé un bloc de code individuel, puis une fois que celui-ci était fonctionnel, je les ai assemblés pour obtenir le résultat final qui combine ces trois fonctions.
Les différentes étapes que suivra le programme en fonction des cas qui lui sont soumis, sont illustrées dans le schéma ci-dessous, afin de donner une vue d'ensemble du processus qui permet d'analyser et modifier des fichiers.
 Schéma résumant les principales étapes du programme
Schéma résumant les principales étapes du programme
Après avoir extrait le fichier XML, il nous reste encore un problème à résoudre pour accéder au texte: un fichier XML ne contient pas le texte en un seul bloc étant donné que c'est un langage de type "markup" (Langage qui utilise des tags afin de structurer le contenu d'un document. Le contenu se trouve entre deux tags et il faut donc procéder à une séparation pour y accéder).
Après avoir extrait ce fichier, il faut donc passer au travers de celui-ci grâce à la librairie xml.etree.ElementTree qui permet d'accéder à son contenu sous forme d'arborescence (chaque nœud correspond à un tag ouvrant). Ensuite, la fonction iter() permettra de passer par chaque noeud de l'arborescence pour en extraire le l'éventuel texte en clair qui se trouve immédiatement après le tag ouvrant ou fermant grâce respectivement à la fonction item.text ou item.tail. Ces fonctions donnent ce texte sous forme de string ou retournent None si il n'y en a pas. Pour plus de détails sur le fonctionnement de cette librairie le lien vers sa documentation est disponible (ainsi que celles des autres librairies) dans les références.
Or, ce qui nous intéresse sera les cas ou il y a du texte a traiter, d'où la nécessité de la ligne de code if (text.tail != None): qui permet de ne traiter que les cas ou le string n'est pas un élément vide, donc les cas ou il y a du texte directement après les tag ouvrants ou fermants. Sans cela, le programme essayerait de traiter une string vide, ce qui le ferait planter. On crée ensuite une liste qui contient tout les mots du texte grâce à la portion de code suivante:
Code qui permet d'indexer tout les mots du texte dans une liste:
for text in tree.iter():
if (text.tail !=None):
wordlist = wordlist + (re.split('; |, |: | ',text.tail))
if (text.text != None):
wordlist = wordlist + (re.split('; |, |: | ',text.text))
wordlist = list(filter(None,wordlist))
Ici, tree sera l'objet issu de xml.etree.ElementTree.parse appliquée au fichier XML qu'on aura extrait (content.xml pour un fichier .odt ou document.xml pour un fichier .docx). On passe donc au travers de chaque nœud de tree et, si la string qui vient après le tag n'est pas nulle, on le sépare en une liste de mots grâce a la fonction re.split qui permet de séparer les éléments d'une string, en fonction d'un critère donné (ici les espaces, les points etc...), en une liste d’éléments. Cette liste comportera donc l'ensemble des mots du texte, d’où on va ensuite extraire ceux qui apparaissent trop souvent (en fonction du rapport #de fois que le mot apparaît/# de mots total qui devra être plus faible qu'une certaine valeur définie au préalable) pour les indexer dans une nouvelle liste.
A partir de la, on va chercher quand ces mots apparaissent dans le fichier XML et on demande à l'utilisateur s'il veut les remplacer, tout en proposant une liste de synonymes potentiels. La liste de synonymes est obtenue de la base de données "WordNet", à laquelle on accède grâce à la librairie nltk. Une fois cette étape accomplie, il devient aisé de chercher quand un mot de la liste apparaît dans le fichier XML, grâce au code suivant:
Code qui permet de trouver quand un mot apparaît dans un fichier XML
for words in listofexcessivewords:
tree = xml.etree.ElementTree.parse('content.xml')
for item in tree.iter():
item.text.find(words)
item.tail.find(words)
et le remplacer par l'input de l'utilisateur. Pour finir, on recrée une copie du fichier d’origine que l'on "construit" avec tout les éléments contenu dans le fichier zip d'origine, sauf le fichier XML qui contient le texte, que l'on va remplacer avec notre version, précédemment modifiée, grâce au code suivant(1):
Code qui permet de rezipper un file avec la version modifiée du fichier XML
for item in input_file.filelist:
if item.filename != "content.xml":
output_file.writestr(item, input_file.read(item.filename))
....
opérations de modification sur le fichier XML
....
output_file.write("content.xml")
Ainsi, on aura un nouveau fichier, identique en tout point à celui de départ à part le texte qui aura été modifié par le programme, qui devrait être "nettoyé" de toute répétition excessive. Le fichier content.xml qui est réécrit dans l'archive zip est celui qui a été modifié par le programme. Ce code n'a donc changé que le fichier content.xml dans l'archive zip ce qui explique pourquoi la seule chose qui change entre les deux fichiers sera le texte.
Une grosse erreur à laquelle j'ai été confronté pendant la réalisation du projet a été, qu'assez bêtement, au début, je n'ai pas réfléchi au fait que le format XML est un langage de type "markup" et donc que le texte n'est pas en un seul bloc. Ainsi, j'ai initialement écrit un programme basé sur la fonction writelines() qui ne fonctionne que pour des simples fichiers de texte en bloc suivi, puisqu'elle écrit ligne par ligne. Après m'être lancé pleinement dans ce projet et être arrivé au bout de cette première version du programme (qui me paraissait étrangement simple) je me suis aperçu de la grosse erreur que j'avais fait et j'ai été très frustré de voir que mon travail semblait inutile.
Cependant, je me suis rendu compte, dans un second temps, que cette erreur assez naïve m'avait permis de me familiariser avec la librairie nltk et le comptage des mots et, ainsi, d'avoir une maîtrise solide de la procédure d'analyse d'un fichier sur laquelle me reposer pour la suite. Cela m'a donc facilité le travail quand il fallait écrire une procédure similaire pour des fichiers XML et que je faisais face à des difficultés liées à ce format. En plus, elle m'a fourni, involontairement, une manière de modifier aussi les fichiers .txt et ainsi avoir un programme plus complet que prévu.
Une des difficultés principales lors de la réalisation de ce projet a été premièrement de comprendre le fonctionnement de la librairie xml.etree.ElementTree car initialement je suis passé par une solution qui exploite la fonction findall() de la librairie xml.etree.ElementTree. Cette fonction permet de trouver tout les éléments contenus dans un certain tag du XML et, ensuite, d'appliquer la même procédure pour substituer chaque éléments.
Cette approche pose deux problèmes importants: premièrement, le nom des tags qui contiennent le texte ainsi que leur namespace (élément qui permet d'éviter la confusion entre deux tags avec le même nom) varient en fonction du format du fichier à traiter (.odt, .docx, etc...). Il aurait donc fallu ajouter des variables supplémentaires pour chaque type de fichier, chose qu'on évite avec la version finale du programme,. Deuxièmement, et de manière plus grave, cette approche néglige le fait que les nombres ont un sous-tag en plus de celui destiné au texte. Ainsi, on se retrouvait souvent avec un tag correspondant à un nombre à l'intérieur du tag correspondant au texte ce qui rendait inefficace la fonction findall() car elle ne savait pas comment traiter le tag correspondant au nombre et donc elle rendait la totalité du programme non-fonctionnel dès qu'un nombre était contenu dans le texte. C'est pour éviter ces problèmes que j'ai opté pour une solution basée sur les fonctions item.text et item.tail.
Une dernière difficulté a été celle de réussir à re zipper un fichier à partir de l'ensemble des fichiers contenus dans l'archive zip mais avec un fichier (celui du contenu) qui ait été modifié. En effet, au début, j'étais très frustré de voir que le fichier semblait avoir été enregistré correctement, puis d'essayer de l'ouvrir et recevoir le message que le fichier était corrompu et donc non accessible. Au final, j'ai réussi, en me baladant un peu sur des forums, à trouver la solution (1) mentionnée précédemment.
Ce code permet de remonter le fichier zip avec touts les fichiers de l'archive zip originale sauf le document XML qui contient le texte (ici content.xml) qui aura, entre-temps, été modifié par le reste du programme avant d'être remis dans l'archive zip. Ma satisfaction était immense car toutes les pièces du puzzle (dézipper, proposer synonyme + modifier et, enfin, rezipper) étaient enfin là et il ne me restait qu'à les assembler pour que le programme fonctionne.
3. Résultats
Au final, le programme permet donc d'analyser et modifier des fichiers en format .odt, .docx et .txt, tout en proposant des synonymes pour les mots à remplacer. Il faut noter qu'il serait assez aisé d'ajouter d'autres extensions de type "Open Document", elles utilisent toutes un fichier XML pour stocker le texte. Il suffirait donc de trouver le nom sous lequel ce fichier XML apparaît dans l'archive zip et ajouter une variable correspondant à ce nom.
Pour illustrer les résultats obtenus prenons comme exemple le texte aléatoire dans un fichier format .odt illustré ci dessous:
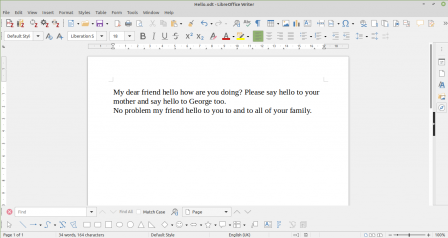 Texte d'exemple dans l'éditeur LibreOffice
Texte d'exemple dans l'éditeur LibreOffice
On peut constater que le mot "hello" est utilisé trop souvent. Ici, pour mieux illustrer le concept, même d'une façon exagérée et clairement visible à l’œil nu, qu'il serait aisé de corriger à la main. Le programme, cependant, est capable de faire les mêmes opérations pour des textes plus longs où les répétitions ne sont pas aussi facilement détectables.
C'est donc sur ce texte que le programme va procéder à toutes les opérations d'analyse du fichier XML pour ensuite proposer à l'utilisateur de changer les mots dont la fréquence est trop élevée.
Ce procédé de changement est illustré ci dessous:
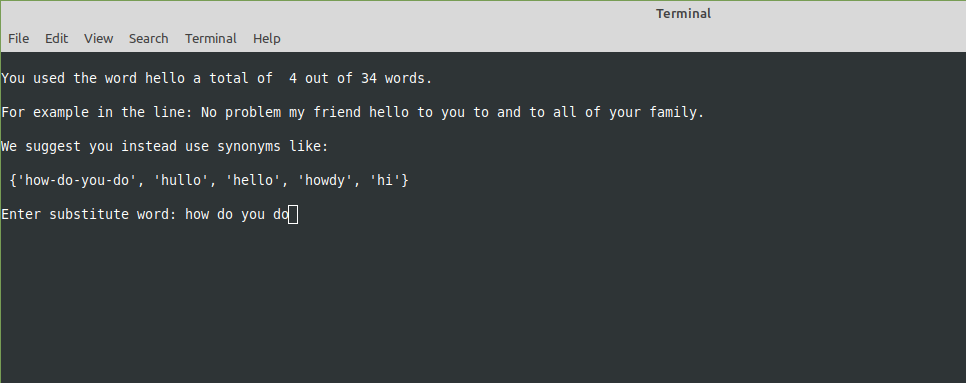 Le programme propose à l'utilisateur de faire des substitutions pour les mots trop souvent utilisés
Le programme propose à l'utilisateur de faire des substitutions pour les mots trop souvent utilisés
Le programme propose d'abord d'insérer un mot à la place de celui dont la fréquence est jugée excessive (l'utilisateur peut aussi remettre le même mot s'il le souhaite); ensuite, il va remplacer le mot par l'input de l'utilisateur dans le fichier xml, répéter l’opération pour tous les mots ciblés et, enfin remonter l'archive zip sous un nouveau nom afin d'obtenir un nouveau fichier comme illustré ci-dessous:
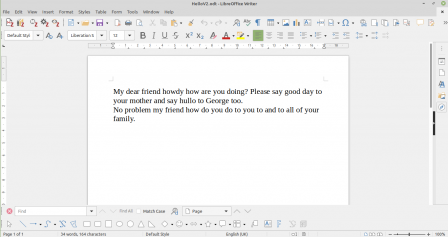 Le texte d'exemple après que l'utilisateur ait fait les changements voulus
Le texte d'exemple après que l'utilisateur ait fait les changements voulus
Au final on obtient donc un texte identique au texte initial en tout points sauf les mots qui auront été substitués selon les indications de l'utilisateur. Ce texte sera sauvegardé dans un nouveau fichier avec un autre nom, plutôt que de remplacer le document initial, afin de permettre à l'utilisateur de conserver la version initiale en cas de besoin ainsi que d'éviter que, dans le cas où le programme plante, le fichier soit corrompu et ainsi que tout le travail devienne irrécupérable.
4. Discussion
Trois éléments principaux ont motivé le choix d'écrire ce programme pour des textes en anglais: 1. une base de donnée complète et intuitive à utiliser était disponible; 2. l'anglais est une langue qui occupe de plus en plus une place prédominante dans le monde et donc faire ce projet en anglais me semblait plus pertinent et intéressant d'un point de vue global; 3. d'un point de vue personnel, cet outil m'est plus utile en anglais qu'en français, langue où mon vocabulaire est plus riche.
Quant au résultat obtenu à proprement parler, il est intéressant car le programme est très intuitif à utiliser et il permet de traiter des textes assez efficacement . Bien que cet outil me semble efficace pour des textes de longueur moyennes (lettres etc...), je ne pense pas qu'il soit encore adapté au traitement de très long textes (manuscrits etc...), car il faut passer en revue toutes les phrases où un mot utilisé excessivement apparaît (ce qui peut se révéler très long si le texte lui même est long). Une autre petite critique personnelle est que, malheureusement, n'ayant pas pu trouver d'étude qui suggérerait à partir de quel fréquence un mot est utilisé excessivement, j'ai du décider de cette valeur en suivant un peu mon instinct. En effet, personnellement, je pense qu'à partir d'une fréquence d'utilisation d'environ 1/20 ( soit 5% du temps) je commence à remarquer les répétitions et j'ai donc fait le choix de fixer la limite à cette valeur. Cependant, la valeur correspond à une variable il serait donc très facile de la moduler à l'avenir afin de l'adapter aux besoins si on se rend compte qu'elle n'est pas forcément adaptée.
Pour contrer cela, on pourrait imaginer une solution future où le programme ne traite qu'un paragraphe à la fois ou dans lequel on pourrait sélectionner certaines parties du texte à analyser afin d'éviter de devoir passer par l'entier du document.
Cette solution pourrait être intéressante à implémenter, et je pense qu'elle rendrait cet outil plutôt complet et adapté à une utilisation en toute circonstances qui pourrait véritablement se révéler utile. Une autre option future pourrait être d'implémenter une fonction qui permet d'avoir l’intégralité d'une phrase comme input par défaut (que l'on pourrait modifier) et ainsi pouvoir faire des modifications à notre guise dans une phrase entière plutôt que de seulement pouvoir remplacer le mot (cela pourrait être par exemple utile pour modifier certaines tournures de phrases pour les adapter au nouveau mot que l'on va implémenter).
En outre, je pense qu'il pourrait être intéressant, à l'avenir, d'incorporer d'autres éléments pour rendre le programme plus complet, comme par exemple un correcteur orthographique. Dans une évolution ultérieure, on pourrait envisager une fonctionnalité d'analyse du texte qui essaye de deviner le sujet global du document. En analysant l'ensemble des mots qui sont présent on pourrait déterminer quels sont les termes récurrents et supposer un thème en fonction de la fréquence de ceux-ci appartenant à un certain champ lexical. Bien sûr, cette dernière idée s'éloigne un peu de ce que j'ai fait durant ce projet mais l’idée me semblait intéressante et je pense que, dans d'éventuels développements futurs, je pourrais essayer d'implémenter cette option en plus car elle pourrait se baser sur un code vaguement similaire à ce que j'ai du faire pour le programme de détection de répétitions.
De manière semblable, on pourrait aussi imaginer un programme qui pourrait essayer de déterminer, grâce à un code similaire au mien, la difficulté d'un texte en se basant, par exemple, sur la loi de Zipf. Ce concept étant assez long à expliquer le lien vers la page Wikipédia de celui-ci est disponible dans les références pour les intéressés. Mais, en simplifiant beaucoup, la loi de Zipf essaye de déterminer le degré difficulté d'un texte en fonction de la différence de fréquence d'utilisation entre les mots les plus utilisés. Étant donné que cette loi se base sur le comptage des mots dans un texte je trouvais intéressant d’illustrer comment mon programme pourrait servir, du moins en partie, de modèle sur lequel se baser.
Je ne développerai pas plus ce sujet à cause de sa complexité mais le lien me semblait tout de même intéressant à faire et, peut-être, cela pourrait éveiller un intérêt chez quelqu'un d'autre qui pourrait éventuellement se lancer dans le développement d'un programme se basant sur cette loi. A noter qu'il existe d'autres lois que celle de Zipf, aussi basées en partie sur le comptage des mots, pour estimer la difficulté d'un texte. J'ai juste choisi celle-ci pour illustrer une autre possibilité éventuelle qui pourrait se baser, en partie, sur mon code.
5. Conclusion
Au vu des résultats obtenus mon objectif initial n'a été que partiellement atteint car le développement de cet outil devait me permettre surtout de traiter de longs textes qui sont plus ennuyeux et fatigants pour moi à "nettoyer" de leurs répétitions. Je dis partiellement atteint car, bien que ce programme facilite un peu la tâche et reste plus commode que de devoir faire des modifications manuellement, ça reste assez long de traiter des textes conséquents et cela peut aussi se révéler très monotone.
Ainsi, je pense qu'il est possible, sans trop de difficultés supplémentaires, de trouver une solution qui, comme dit dans le passage précédent, permettrait de n'analyser que certains passages choisis du texte afin de rendre le processus moins lourd et long. Les résultats sont assez encourageants et efficaces pour espérer améliorer le programme pour qu'il me soit vraiment utile et que je puisse même, éventuellement, l'utiliser lors de mes mes études avenirs.
Outre à l'aspect purement pratique de ce programme, ce projet m'a beaucoup aidé à progresser en python et je me suis beaucoup familiarisé avec les petites astuces et le mode de fonctionnement. En particulier, il m'a aidé a comprendre avec plus de clarté comment utiliser les boucles for afin de faire travailler l'ordinateur pour nous en lui faisant faire un grand nombre d'opérations longues et répétitives, ce qui permet de considérablement simplifier notre tâche en tant qu'être humain.
Mais, aussi, comment écrire des programmes qui soit un peu plus complexes qu'un simple programme "linéaire" (qui exécute juste une suite de lignes de code sans aucune intervention de l'utilisateur ou variations externes auxquelles le programme doit pouvoir réagir) ce qui permet de grandement élargir le champ de possibilité que peut m'offrir un langage comme python avec la possibilité d'écrire des programmes qui dépendent de facteurs extérieurs et pas simplement de certains éléments prédéfinis. Dans ce sens, je dirai que ce programme a été assez intéressant à réaliser et que, malgré les nombreuses difficultés qui m'ont beaucoup frustré au départ, je suis satisfait de ce que j'ai produit et j'ai tout de même réussi à prendre du plaisir à faire ce projet.
Comme je l'ai dit, ce projet a participé à me montrer à quel point les opportunités peuvent être vastes en informatique, même avec un niveau relativement peu élevé comme le mien. Une autre chose que ce projet m'a appris est l'utilité de programmer en plusieurs "morceaux" de codes afin de pouvoir faire du error handling sur des petites portions de codes et, de cette manière, s'apercevoir plus rapidement et avec plus de facilité d’où viennent exactement les erreurs. Cela m'étais très compliqué avant car j'essayais de tout coder en un coup et donc cela me faisait perdre inutilement beaucoup de temps et d'énergie à essayer de comprendre d'où vient une erreur dans un code très long et peu structuré.
Un autre élément du error handling que j'ai appris, et qui peut sembler très simple, voir stupide pour quelqu'un qui a des connaissances en informatiques, mais qui pour moi a été une grande découverte, est le fait d'utiliser, dans un code python, la fonction "print" afin de vérifier si une opération a pu être réalisée ou non. Je me rends compte à quel point cela peu paraître banal mais ça m'a été très utile car le fait d’acquérir cette technique comme un réflexe systématique, je n'arrivais pas à le faire avec régularité auparavant, a été un véritable "gamechanger" qui me permet de rédiger un code bien plus fluidement et repérer les erreurs avec beaucoup plus de facilité. Ce projet, tout comme le premier, a donc plutôt été un outil pédagogique en informatique qu'un brillant succès en codage.
Je dis cela car les deux programmes que j'ai écrit sont certes fonctionnels, dans une certaine mesure, mais ils restent assez simples et ils pourraient être améliorés avec des connaissances un peu plus approfondies dans le domaine et plus de temps et d’énergie à consacrer à ce projet (car cela reste un projet dans le cadre scolaire sur un assez court terme ce qui limite forcément le temps qu'on peu y dédier.) Mais, d'un point de vue personnel, je considère ce projet comme un succès car bien que je savais que je n'allais probablement pas écrire un programme qui pourrait réellement me servir, je n'en suis pas encore là, il a été un bon prétexte pour me motiver à m'intéresser à l’informatique (sujet qui me sera utile dans mes études futures) et essayer de comprendre plus en profondeur comment elle fonctionne, quels sont les mécanismes derrière.
Je me suis même surpris à prendre du plaisir à coder et ressentir une profonde satisfaction quand une solution à un problème auquel je faisais face arrivait enfin et que le programme faisait enfin ce qu'il était censé faire et pas autre chose. Pour résumer, ce code m'a surtout été utile pour m'épanouir (je sais que c'est un peu exagéré mais je ne trouvais pas d'autre terme qui pourrait mieux exprimer ce concept) dans le domaine de l’informatique et me faire découvrir les côtés plaisant de ce sujet que d'autres branches n'ont pas forcément.
Références
https://docs.python.org/3/library/xml.etree.elementtree.html https://docs.python.org/3/library/re.html https://docs.python.org/3/library/os.html https://docs.python.org/3/library/zipfile.html https://www.guru99.com/wordnet-nltk.html https://www.tutorialspoint.com/python/string_replace.htm https://stackoverflow.com/questions/4998629/split-string-with-multiple-delimiters-in-python https://en.wikipedia.org/wiki/Zipf%27s_law